

- 画像生成AIが絵や写真を生成する大元の仕組みがわかる
- 拡散モデルの仕組みが直感的にわかる
- 画像生成以外の応用例を知れる
画像生成AIって元のデータをパクってるの?どうゆう仕組み?
パクってはないですが、参考にしてますね。
何かと話題に上がっている画像生成AI。今回はAIが画像生成する仕組みのうち、その安定した再現力と応用範囲から広く活用され始めている拡散モデルという仕組みについて図説します。
拡散モデルの画像生成の仕組み
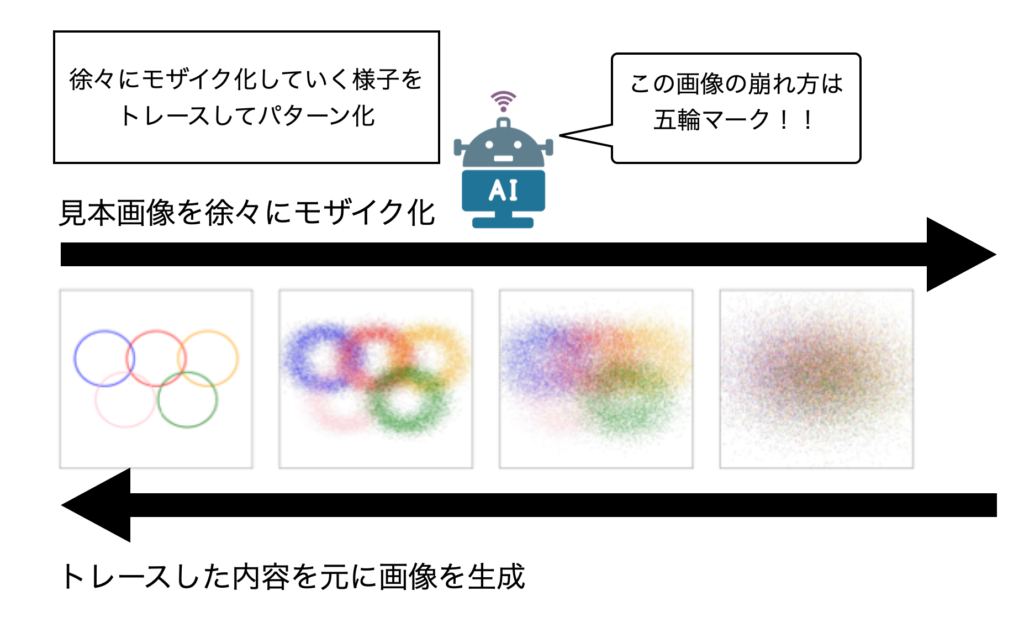
Diffusion Normalizing Flow(2021)より画像を一部引用して作成
拡散モデルの画像生成の仕組みはものすごくざっくり言うと以下の3ステップです。
- 見本画像に徐々にノイズを入れてモザイク化する様子をAIにたくさん学習させる
- 同時に文字と画像が紐づく情報をたくさん学習させる
- トレースした内容を逆にたどらせてノイズからの画像復元を目指させる
※便宜的にノイズ注入過程をモザイク化と表現
拡散モデルの場合、AI自体は画像復元を目指しています。ただ、開発側の目標は復元ではなく画像生成です。そこで、単語や文に大量の画像データを紐付けてAIに膨大な学習を積ませることで多種多様な画像生成ができるようにしています。
拡散モデルはノイズの入れ方を工夫することで安定してパターンを学習できる点がメリットです。ただ、計算量が膨大になることがデメリットでした。このデメリットを解消するために計算量の圧縮法を取り入れているのが無料でサービス提供しているStable Diffusionという画像生成AIです。
その他応用例
拡散モデルは、画像生成以外でも活用が期待されています。
例えば画像復元や修復の分野です。古い写真や劣化した画像を、拡散モデルを使って高品質に復元することができます。歴史的な写真やアート作品の保存に役立つことが期待されます。
また、テキストからの音声生成や3D画像生成にも応用できる可能性が論文で報告されています。

テキストから3Dデータを生成する論文についてはSONY研究所の方がYouTubeで解説してくださっています。
計算コストをいかに圧縮してお手頃な価格でサービスを提供できるかが拡散モデルを利用した生成系AIの発展の鍵となりそうです。
まとめ
今回は今話題になっているStable Diffusionでも使われている拡散モデルの仕組みについてお話ししました。
画像にノイズを加えて徐々に崩れていくパターンを学習させて、その過程を逆回しする発想が天才的ですね。
拡散モデルの応用範囲の広さがどこまで実社会に実装されるかも注目です。
今回は以上になります。ここまで読んでくださりありがとうございました。