

- チャットGPT(ChatGPT)がスームズに会話できている理由がわかる
- 会話特化AIの大まかな歴史がわかる
- 仕組みを理解することで今までの技術の積み上げだとわかる

機械が人間みたいに喋るなんて、なんか怖い。
技術自体はすでに生活の色んな場面で活用されているんです。
チャットGPTの仕組み
結論から言うと、チャットGTPは統計と学習モデルの組み合わせで人間のような会話ができているAIです。
今までと異なるのはその学習量と訓練が異次元ということです。何億円という莫大なコストをかけて大量文章をAIに学習させて、適切な回答ができるように訓練をすることで生まれました。
チャットGPTは大規模言語モデルという学習方法を利用して誕生しました。この大規模言語モデルという学習方法を用いたサービス自体はすでに各社出していて、コールセンターの効率化やマーケティング、さらには製品開発などのサポートで活用されています。
この大規模言語モデル誕生の歴史をたどりながらチャットGTPの仕組みについてお話しします。
大規模言語モデルの歴史
言語モデルは、過去数十年にわたって研究されてきましたが、その歴史は以下のように進展してきました。
 にゃん太
にゃん太会話の中で「今日の天気は」の次に一番登場する確率が高い単語出してや!

晴レ
にゃん太よしよし、でも複雑な文は作れんなぁ
にゃん太とりあえず文章たくさん読み込ませるから、似た文章が来たらそれっぽく回答してや!
いつもお世話になっております。営業部のAIでス。
にゃん太よしよし、定型文はいけそうや。けど専門分野が変わると全然だわ
にゃん太めっちゃ文章読み込ませるから単語同士の関連性の強弱を勉強しいや!文脈もわかるように離れた単語同士の関連性もよろしくな!
簡単なテストなら解けるデ
にゃん太イケる!!
にゃん太あとは物量や!めっちゃ金かけて文章読ませて、訓練もしっかりするで!
アイアム、ChatGPT!司法試験も合格できるデ
にゃん太めっちゃ賢くなったわ
だいぶデフォルメして記載してしまいました。。めっちゃ詳しい方すみません。もう少し詳しくそれぞれについてお話しします。
高校数学で習う確率を利用した単語予測(初期言語モデル)

初期の言語モデルは、単純なルールやパターンに基づいて文章を生成していました。初期のモデルは、単語の組み合わせや一般的なフレーズを使って、簡単な文章を作成することができました。例えば、「こんにちは、私は太郎です。」や、「今日の天気は晴れです。」のような簡単な文です。
この文の生成で用いられていた考え方が条件付き確率です。
「今日の天気は、」という文の次に来る単語の確率を算出して、確率が高い単語を出力する仕組みです。
感覚的に考えても「今日の天気は」の次に来る単語は「晴れ」や「曇り」、「雨」などで、「東京」という単語が来ることは文脈的にほぼあり得ないですよね。その出現確率を数値化してより高い確率の単語が出力できるようにしていました。

初期の言語モデルは高校数学の確率で説明できるんだね
ただ初期の言語モデルは限定的な知識しかなく、現実の会話には対応できませんでした。
初期の言語モデルを活用したサービスの具体例としてチャットボットがあります。当時のチャットボットは、単純な質問に対しては適切な回答ができましたが、より複雑な質問や状況への対応は無理でした。
また、初期の言語モデルは文法や単語の使い方にも課題がありました。適切な単語を選ぶことが難しく、時には意味の通じない文章が生成されることもありました。
例えば、「昨日は、私は映画を見ました。」という文を生成しようとすると、「昨日、私映画見た。」のような人間らしくない文が生成されることがありました。
このような課題を克服するために、研究者たちは言語モデルの精度を向上させる方法を探求し続けました。探求の中で機械学習の技術を応用することで、言語モデルは大きく進化しました。
大量の文章を取り込んでパターン化(機械学習の登場)
機械学習技術が登場したことで、コンピュータは大量のテキストデータから文章のパターンを学習・識別することが可能になりました。
これにより、より自然な文章を生成できるようになりましたが、課題がありました。
機械学習による文章生成では、文脈に応じた適切な表現を選ぶことが難しかったり、特定の専門用語や表現が正確に理解されないことがありました。そのため、生成された文が、時には曖昧であったり、意図しない意味になることがありました。
機械学習を用いたサービスの具体例に電子メールの自動返信機能があります。受信したメールの内容に基づいて、適切な返信文を生成することが求められます。機械学習を活用することで、コンピュータはメール内容のパターンを識別して、定型文的な返信をすることはできるようになってきました。
より自然な文を生成できるように、研究者たちはさらに高度な言語モデルの開発を進めました。
脳みそを真似た学習モデルの登場(ニューラルネットワークの進化)

より高度な言語モデル開発で有効だったのが、人間の脳の神経回路を真似たニューラルネットワークという学習モデルです。ここ最近のAIの能力を飛躍的に引き上げたディープラーニングという手法の土台となるモデルです。
人工ニューロンと呼ばれる単位で構成され、入力データを受け取り、より適切な出力を生成することができます。単純な機械学習と異なる点は入力データのひとつひとつ関連性の強弱(重みづけ)を学習できる点です。
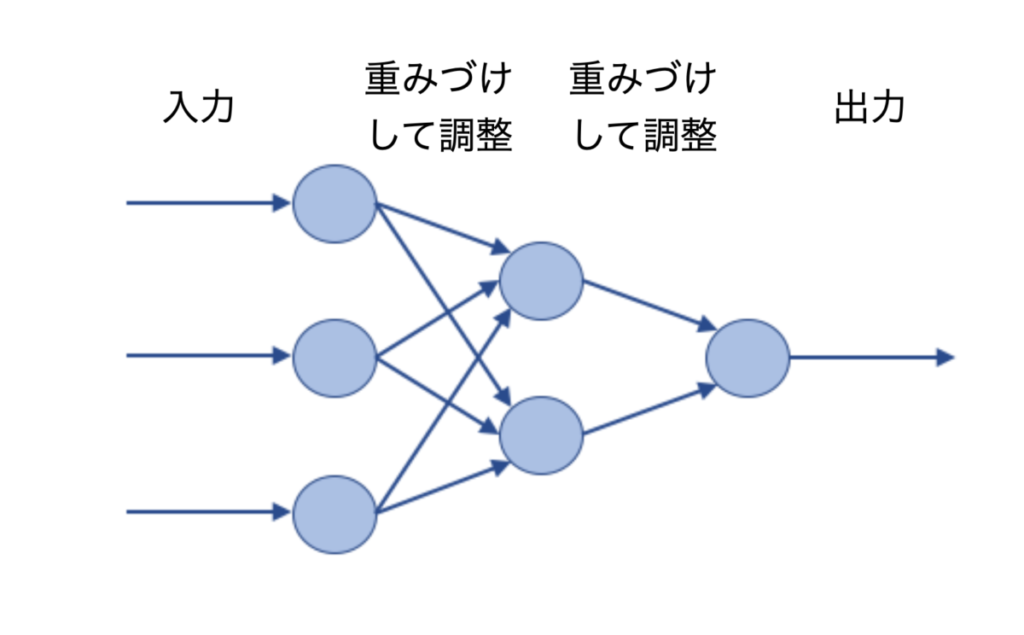
ニューラルネットワークの進化により、大量のテキストデータを処理し、より複雑な文脈を理解し、自然な文章を生成できるようになりました。
文章の生成精度が向上した一方で、ニューラルネットワークの進化は入力から出力に至るまでのプロセスをブラックボックス化しました。
上のイメージ図のように人工ニューロンの数が少ない簡単なモデルなら関連性の強弱についても追い切れます。ですが、実際は人工ニューロンの数を増やしたり、入力データから出力するまでの間に関連性の強弱を調整するステップを何個も挟むために、なぜその入力データから適切な出力データが出るのか全容を把握しきれなくなりました。
このニューラルネットワークがさらに進化して大規模言語モデルが登場しました。
学習モデルの大規模化とチャットGPTの正体

大規模言語モデルは近年のデータベースの大容量化や情報処理の高速化により実現しました。これによりさらに人間に近い文章を生成できるようになりました。
このモデルは、インターネット規模の膨大なテキストデータから言葉の関連性の強弱を学習することで、人間のような理解力と表現力を持っています。この膨大な学習に加えて、適切な回答ができるように訓練を施したのが最近話題になっているチャットGPTの正体です。
一方で、チャットGPTが吐き出した言葉の真偽は学習データや訓練の内容に依存するため、平然と嘘をついたように感じる文章を作成することがあります。
そのため、現時点では情報の正誤を判断できる専門家の補助ツールとしての活用や、プログラムの内容が決まっている教育事業での利用がなされています。
まとめ
今回チャットGPTの仕組みについてお話ししてきました。統計と学習モデルの発展が文章生成の土台としてあり、異次元の物量と訓練によってその性能を担保することで誕生したのがチャットGPTです。
めっちゃざっくりと言うと以下の流れで誕生しました。
にゃん太会話の中で「今日の天気は」の次に一番登場する確率が高い単語出してや!
晴レ
にゃん太よしよし、でも複雑な文は作れんなぁ
にゃん太とりあえず文章たくさん読み込ませるから、似た文章が来たらそれっぽく回答してや!
いつもお世話になっております。営業部のAIでス。
にゃん太よしよし、定型文はいけそうや。けど専門分野が変わると全然だわ
にゃん太めっちゃ文章読み込ませるから単語同士の関連性の強弱を勉強しいや!文脈もわかるように離れた単語同士の関連性もよろしくな!
簡単なテストなら解けるデ
にゃん太イケる!!
にゃん太あとは物量や!めっちゃ金かけて文章読ませて、訓練もしっかりするで!
アイアム、ChatGPT!司法試験も合格できるデ
にゃん太めっちゃ賢くなったわ
ニューラルネットワークという学習モデルが有望だと判断したあとは地道にお金と時間をかけたんですね。そんな開発者の努力の結晶が無料で試せるのですがからいい時代です。
今回は以上となります。
ここまで読んでくださりありがとうございました。